

In this series of blog posts, we’ve been looking at various ways in which servers present information that can be used by search engines to uniquely identify them. That is, they leave footprints, often very obvious ones. Here at EBN, we take quite a few steps to make sure that the servers hosting our WordPress blogs don’t stand out from the crowd.
So far, we’ve talked about Server headers (these usually present the software powering the webserver, most commonly Apache), X-Powered-By headers (the technology running WordPress, usually a version of PHP), and ASN numbers (these are used to pinpoint the company hosting the server).
This time we’re taking a look at common server default pages which are returned when we enter a server’s IP into our browser. These are default pages which servers show when something’s gone wrong, like when a user clicks on a broken link (meaning it links to something that doesn’t exist, usually because a webpage has been moved or renamed) or a link meant for someone who is logged in to a specific service.
The most typical of these errors is the 404 or Not Found error message. This is the standard HTTP response which indicates that our computer is in contact with the server but that the server couldn’t find whatever it was we wanted. This is typical for a dead link. The response code of 404 is mandatory, but the web page which the server shows can be pretty much anything.
In fact, if we search for 404 error pages, we find quite a few interesting and funny ones. A custom error page is just another way that a website can stand out from the crowd. Webserver software usually has very plain (boring) default error pages which show if the programmer didn’t specify otherwise. If we install Apache, for instance, and don’t bother to set up specific error pages, our users will see Apache’s default page – the one for error 404 looks like this:
Here’s another one, this time for Nginx:
Another common error is 403 – Forbidden. This again means that the server received the request but that it refuses to fulfill it. An example would be a user requesting a directory listing of the server, or an authenticated user attempting to access something which they are not permitted to access. A similar error is 401 – Unauthorized, this means that access to something is restricted and needs authentication in order to access it. The difference is that with the first, so error 403, a user has authentication but is trying to access something which is expressly forbidden, while for the second the user might have access but hasn’t yet provided the necessary authentication.
In our first blog post, we talked about the most typical software used to run WordPress blogs, with a good 40% of all servers running some version of Apache (or at least claiming to according to their server header). This might lead us to believe that the same 40% of servers would return Apache’s default error page for errors such as 404 and 403.
In reality, most webservers are set up to either not return any page at all or to return a custom page. If the server doesn’t return an error page, a browser will show its own default page, such as Internet Explorer’s page for 403 errors:
We’ll note that in some cases, a browser will show its own page regardless of whether or not the server returns one – both Internet Explorer and Google’s Chrome do this if the returned page is smaller than 512 bytes (which default pages used by Apache and other web servers generally are). IE returns different so-called user-friendly pages depending on the version of IE while Chrome replaces the page with Google’s suggestions based on their algorithms.
You can easily check what error page your webpage displays by adding a non-existing page after the site’s address – for instance, if we go to Google.com and add /testing to the URL (so it’s google.com/testing), we’ll get Google’s 404 error page.
Why are we talking about these errors and the response pages we get from them? Like server headers, these pages can be used to footprint a large number of pages (blogs) as coming from a single source. This is something we’re actively trying to avoid.
We once again turn to data collected through Shodan to see how most servers running WordPress respond, that is, what is their default server page. Out of around 800 servers, a bit more than 10% return a 404 page, and fewer return a 403 page (note that the HTTP status 200 means a successful request):
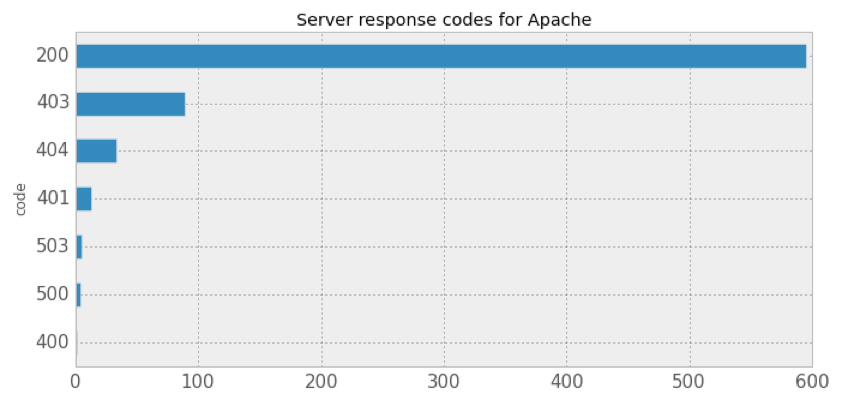
So the most common scenario is not returning an error page. We checked the returned 404 pages for some common words they might contain, and while it’s no surprise that almost all of them include the number 404, other words are included very infrequently:
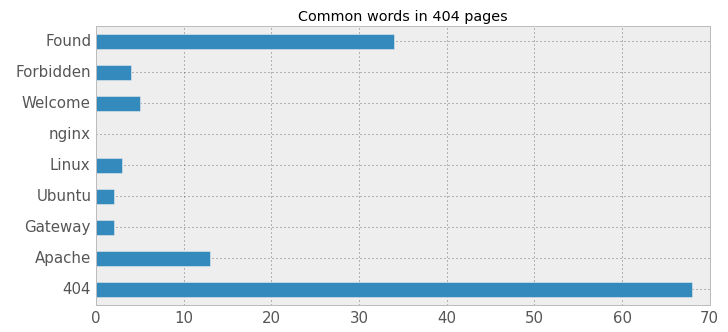
What this means is that 404 pages vary widely among different websites. We found the same thing in 403 error pages:
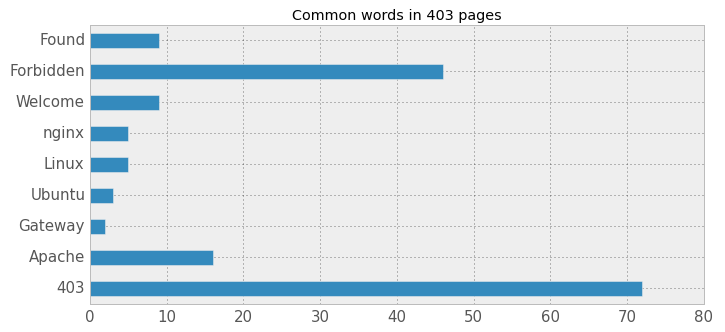
Again, if many different, seemingly unrelated pages return the exact same error page, this could be used as an indicator that the pages are being hosted by a single company or individual.
Most sysadmins set up websites so that they return a default error page only in the case that a user enters an IP directly (so instead of entering the URL such as www.example.com, someone enters an IP address such as 192.168.9.9). The error page can be anything from a 404 or 403 error page, Apache’s default page, the default page of the used distribution (such as Ubuntu Server), etc. This behavior is different from most normal web pages and can be used to single out multiple pages (blogs) as coming from a single source.
Here at EBN, besides having many pages which don’t return 404, 403, and other error pages, we’ve set up random variations of the most common error pages. This means that different blogs and blog networks will serve up different error pages, making it that much harder for search engines to footprint.
We realize that these error pages are a small factor in web pages being identified and leaving footprints for search engines to find, but we are always thinking about and acting on possible threats to PBNs.
